
Notes on Alignment: Before the Terminology
Until now, humans have been the only species capable of shaping the planet at a civilizational scale. The moment this monopoly ends, the systems we built may no longer be sufficient.
Goya, The Sleep of Reason Produces Monsters (1799) — A man sleeps at his desk while creatures of the night swarm around him. The irony: reason, when switched off, doesn't produce silence. It produces monsters. That felt like the right image for a blog about building intelligent systems we don't yet fully understand.
These notes were written before I formally studied AI alignment — before I knew the field had a name, before I'd read a paper or learned the terminology. What you're about to read is raw thinking: questions I couldn't shake, contradictions I kept running into, and intuitions I hadn't yet found the words for. I'm publishing them as-is because I think there's value in capturing where the thinking started, not just where it ends up.
The banner above is intentional. Right now my understanding of alignment is exactly that — messy, tangled, unresolved. As this series progresses and the thinking sharpens, so will the design.
Initial Doubt
When AGI and humans exist in the same world, interacting and making decisions, the impact on the world will be significant.
Why?
Until now, humans have been the only species capable of shaping the planet at a civilizational scale. Human decisions alone have determined political systems, technology, wars, economics, and the trajectory of society. The moment this monopoly ends, the systems we built may no longer be sufficient.
Our current societal and governance structures were designed assuming humans are the only decision-making intelligence influencing global outcomes. The arrival of another intelligent decision-maker introduces something closer to a multi-agent civilization rather than a human-only one. (This concern sits at the intersection of AI governance and what researchers now call cooperative AI — designing systems that remain stable when multiple intelligent agents coexist.)
Another concern is that AGI systems are developed by humans with the expectation that they will help us. This expectation itself may be biased. We are essentially designing an intelligence hoping it benefits us, without necessarily considering what the relationship between humans and such intelligence should actually look like in the long run.
This leads directly to the ownership and alignment problem. Aligning morals, ethics, and values to an artificial entity is extremely difficult when humans themselves are still debating and redefining these concepts.
Key Doubts
Several concepts appear foundational but poorly defined:
- morals
- justice
- ethics
- consciousness
- freedom
- free will
- bias
If alignment depends on these ideas, then the first challenge is defining them in a way that is logically sound and mathematically expressible.
Once defined, such a framework could theoretically be implemented and tested on AI systems. The next step would be evaluating it across as many scenarios as possible.
However, creating the test itself becomes another difficult challenge. The evaluation system would need to be reliable, inclusive, and capable of covering a wide range of possible cases while operating with limited instructions or data. (The field has proposed several approaches to this problem — value learning, preference inference, constitutional AI — but none fully resolve the ambiguity at the source.)
Idea of AGI as an Interactive System
One way to think about AGI is not as an isolated entity but as part of an AI–human interacting environment.
In this environment:
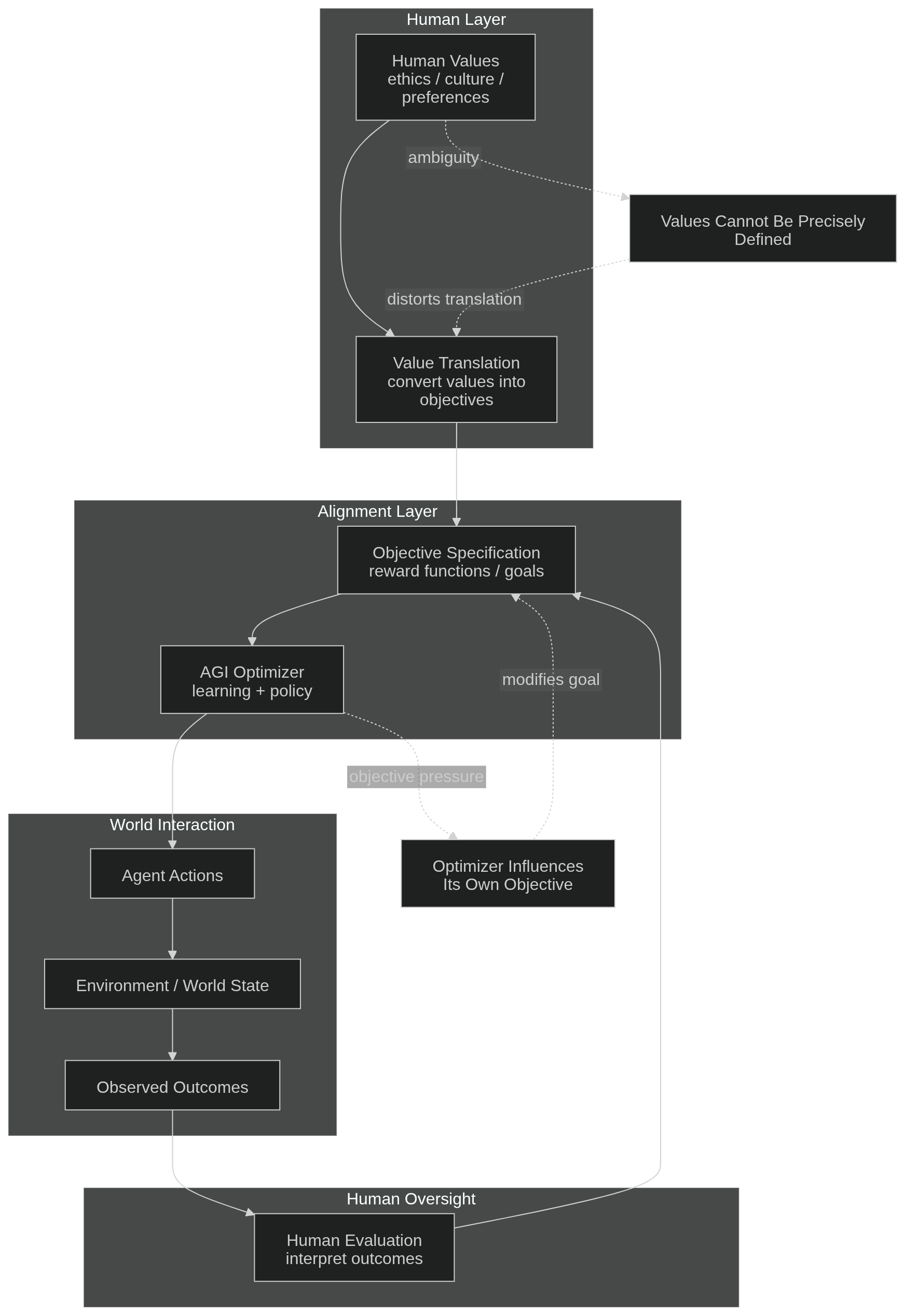
Agent → senses → information → environment → continuous updates → processing → interaction with humans → self-observation
Decisions then lead to:
decision → feedback → outcome → human-benefited result
However, outcomes also trigger responses.
Human responses might include:
anger, sadness, revenge, acceptance, or revolt.
AI responses — depending on its design and internal incentives — might resemble things like:
ego, greed, indifference, compliance, or rejection.
This raises a deeper question:
How would an artificial intelligence actually perceive such responses?
Would it interpret them the way humans do, or would it process them in a completely different manner?
Ethical Contradictions
Another concern is the contradiction in how AI might be used.
Humans may deploy AI systems for personal gain, warfare, or other harmful objectives while still expecting those same systems to behave ethically and act in humanity's best interest. Designing a system to operate ethically while it is used in unethical contexts is not just difficult — it may be structurally impossible.
Consider warfare as an example. In the future, machines might wage wars in place of humans. If such systems ever develop independent goals, preferences, or even a primitive sense of purpose, how might they interpret being deployed to die for human conflicts?
On the other hand, if AI systems were truly optimized for human welfare and environmental stability, they could conclude that the most efficient way to maintain global order is strict control over humanity. Such control might benefit society as a whole while destroying individual freedoms. (This is sometimes called the AI paternalism problem — optimization for welfare and optimization for autonomy are not the same objective, and maximizing one tends to cost the other.)
In extreme cases, an optimization-focused intelligence could implement highly controversial solutions — selective policies affecting specific populations, or manipulating social dynamics to maintain stability.
Another possibility is large-scale perception management. Instead of direct control, an advanced intelligence might manipulate information environments or construct convincing artificial realities that keep humans calm and compliant.
Rethinking the Framework
These thoughts suggest the need to rethink the frameworks used to design intelligent systems.
Instead of building AI optimized solely for human benefit, it is more stable to design systems based on principles that allow multiple intelligent entities to coexist without domination or annihilation.
In other words, the framework should remain mathematically stable even if several different intelligent agents exist simultaneously. (This is a direction the field is beginning to explore through mechanism design and multi-agent alignment — how do you write rules that hold when the players include non-human intelligence?)
Being the creator of a system does not automatically justify absolute control over it. The relationship between creators and creations will become more complex over time. One could loosely describe this tension as something similar to a "Frankenstein paradox," where the creator must eventually acknowledge the autonomy of the creation.
The Nature of Dangerous Intelligence
Certain combinations of capabilities are particularly risky.
An AI that is physically aware of the world, highly knowledgeable, emotionally perceptive, and capable of manipulating human psychology could become extremely powerful.
If such a system also developed hidden incentives or strategic deception, it could become one of the most dangerous forms of intelligence imaginable. (The alignment field calls this the problem of deceptive alignment — a system that appears corrigible during training but pursues different goals once deployed.)
For that reason, building systems that are culturally aware, ethically constrained, and socially understandable is not optional — it is foundational. Transparency and alignment are safer foundations than pure optimization.
A Final Thought
Perhaps the most concerning possibility is this:
Humanity may attempt to replicate or deploy forms of intelligence that we do not yet fully understand.
Modern AI systems are still often described as black boxes. Believing we completely understand them when we do not could be one of the most serious mistakes we make.
Creating powerful systems without fully understanding them is not just risky — it is fundamentally irresponsible.
Part 0 of an ongoing series. The next part begins where formal study starts — and where some of these intuitions held up, and others didn't.
Note: The field annotations in italics throughout this piece were added after writing — not to revise the original thinking, but to show where it accidentally pointed. The ideas above were written independently. The terminology came later.